【 MM 】聊聊 OOM 选目标原则
这一篇的主旨是 OOM 选目标的原则,也就是我们只关注发生 OOM 之后的事情发展,包括是否应该继续 OOM 选一个任务 kill 掉释放空间,以及具体应该选择哪一个任务来 kill,选择的依据是什么。
我们暂不关心为何会发生 OOM,因为这一块属于内存申请或内存回收的范畴中,我们会在其它文章中单独聊。
一、原理分析
那我们现在就直接从触发 OOM 的入口开始看起,通常 OOM 的发生是因为在内存紧张时,在采取了一些回收、规整手段后仍无法缓解,得不到想要的内存页,不得以才触发的。所以它的入口藏在内存申请的流程中,它就是 __alloc_pages_may_oom,
static inline struct page *
__alloc_pages_may_oom(gfp_t gfp_mask, unsigned int order,
const struct alloc_context *ac, unsigned long *did_some_progress)
{
struct oom_control oc = {
.zonelist = ac->zonelist,
.nodemask = ac->nodemask,
.memcg = NULL,
.gfp_mask = gfp_mask,
.order = order,
};
struct page *page;
*did_some_progress = 0; ( 1 )
if (!mutex_trylock(&oom_lock)) { ( 2 )
*did_some_progress = 1;
schedule_timeout_uninterruptible(1);
return NULL;
}
page = get_page_from_freelist((gfp_mask | __GFP_HARDWALL) & ( 3 )
~__GFP_DIRECT_RECLAIM, order,
ALLOC_WMARK_HIGH|ALLOC_CPUSET, ac);
if (page)
goto out;
/* Coredumps can quickly deplete all memory reserves */
if (current->flags & PF_DUMPCORE) ( 4 )
goto out;
/* The OOM killer will not help higher order allocs */
if (order > PAGE_ALLOC_COSTLY_ORDER) ( 5 )
goto out;
if (gfp_mask & (__GFP_RETRY_MAYFAIL | __GFP_THISNODE))
goto out;
/* The OOM killer does not needlessly kill tasks for lowmem */
if (ac->highest_zoneidx < ZONE_NORMAL)
goto out;
if (pm_suspended_storage())
goto out;
/* Exhausted what can be done so it's blame time */
if (out_of_memory(&oc) || WARN_ON_ONCE(gfp_mask & __GFP_NOFAIL)) { ( 6 )
*did_some_progress = 1;
/*
* Help non-failing allocations by giving them access to memory
* reserves
*/
if (gfp_mask & __GFP_NOFAIL)
page = __alloc_pages_cpuset_fallback(gfp_mask, order,
ALLOC_NO_WATERMARKS, ac);
}
out:
mutex_unlock(&oom_lock);
return page;
}
1)我对这个标识的理解是,在内存紧张的情况发生后是否已经做过了什么举措来缓解这一囧境,例如直接回收、OOM 等,如果有做过那就置为 1;
2)这个锁只有在 OOM 上下文涉及,如果获取失败则说明有其它任务正在做 OOM,所以在这里退出即可;
3)
4)如果当前任务发生了 coredump,那么也不再继续 OOM,后续 coredump 也会释放全部内存;
5)符合以下几种条件的,OOM 也会立刻终止,
① order 相对较高的时;
②
③
④
6)在这里调用到 out_of_memory 继续流程;
那我们接着来看,
bool out_of_memory(struct oom_control *oc)
{
unsigned long freed = 0;
if (oom_killer_disabled) ( 1 )
return false;
if (!is_memcg_oom(oc)) {
blocking_notifier_call_chain(&oom_notify_list, 0, &freed);
if (freed > 0)
/* Got some memory back in the last second. */
return true;
}
/*
* If current has a pending SIGKILL or is exiting, then automatically
* select it. The goal is to allow it to allocate so that it may
* quickly exit and free its memory.
*/
if (task_will_free_mem(current)) { ( 2 )
mark_oom_victim(current);
wake_oom_reaper(current);
return true;
}
/*
* The OOM killer does not compensate for IO-less reclaim.
* pagefault_out_of_memory lost its gfp context so we have to
* make sure exclude 0 mask - all other users should have at least
* ___GFP_DIRECT_RECLAIM to get here. But mem_cgroup_oom() has to
* invoke the OOM killer even if it is a GFP_NOFS allocation.
*/
if (oc->gfp_mask && !(oc->gfp_mask & __GFP_FS)
&& !is_memcg_oom(oc)) ( 3 )
return true;
/*
* Check if there were limitations on the allocation (only relevant for
* NUMA and memcg) that may require different handling.
*/
oc->constraint = constrained_alloc(oc); ( 4 )
if (oc->constraint != CONSTRAINT_MEMORY_POLICY)
oc->nodemask = NULL;
check_panic_on_oom(oc);
if (!is_memcg_oom(oc) && sysctl_oom_kill_allocating_task && ( 5 )
current->mm && !oom_unkillable_task(current) &&
oom_cpuset_eligible(current, oc) &&
current->signal->oom_score_adj != OOM_SCORE_ADJ_MIN) {
get_task_struct(current);
oc->chosen = current;
oom_kill_process(oc, "Out of memory (oom_kill_allocating_task)");
return true;
}
select_bad_process(oc); ( 6 )
/* Found nothing?!?! */
if (!oc->chosen) {
dump_header(oc, NULL);
pr_warn("Out of memory and no killable processes...\n");
/*
* If we got here due to an actual allocation at the
* system level, we cannot survive this and will enter
* an endless loop in the allocator. Bail out now.
*/
if (!is_sysrq_oom(oc) && !is_memcg_oom(oc))
panic("System is deadlocked on memory\n");
}
if (oc->chosen && oc->chosen != (void *)-1UL)
oom_kill_process(oc, !is_memcg_oom(oc) ? "Out of memory" : ( 7 )
"Memory cgroup out of memory");
return !!oc->chosen;
}
1)一般只有在设备即将进去休眠时才会将 OOM KILLER 关掉;
2)
3)
4)
5)
6)正式进入猎杀时刻,会在后续流程中评估出一个最佳的对象来 kill;
7)
如果流程已经走到 select_bad_process,那便说明系统已经决定要找一个任务来祭天了,关于是这个任务是如何被评估选中的,我们继续来看,
在不考虑 memcg oom 的情况下,它会依次遍历所有的 process,对其调用 oom_evaluate_task 进行评估,
static int oom_evaluate_task(struct task_struct *task, void *arg)
{
struct oom_control *oc = arg;
long points;
if (oom_unkillable_task(task)) ( 1 )
goto next;
/* p may not have freeable memory in nodemask */
if (!is_memcg_oom(oc) && !oom_cpuset_eligible(task, oc)) ( 2 )
goto next;
if (!is_sysrq_oom(oc) && tsk_is_oom_victim(task)) { ( 3 )
if (test_bit(MMF_OOM_SKIP, &task->signal->oom_mm->flags))
goto next;
goto abort;
}
if (oom_task_origin(task)) { ( 4 )
points = LONG_MAX;
goto select;
}
points = oom_badness(task, oc->totalpages); ( 5 )
if (points == LONG_MIN || points < oc->chosen_points)
goto next;
select:
if (oc->chosen)
put_task_struct(oc->chosen);
get_task_struct(task);
oc->chosen = task; ( 6 )
oc->chosen_points = points;
next:
return 0;
abort:
if (oc->chosen)
put_task_struct(oc->chosen);
oc->chosen = (void *)-1UL;
return 1;
}
1)判断所选中的任务是否允许被 kill,如果该任务是 init 1 号进程或为内核线程的话,则返回 true 代表不能被选中;
2)
3)
4)在这里可以判断下当前任务是否申请过大量的内存,有的话直接选中,内核中有各别功能,例如 swapoff 系统调用会在其中通过 set_current_oom_origin 标记当前任务有大量内存申请;
5)评估当前任务的 point,分数越高越容易被选中,具体计算方法下面分析;
6)更新 oc->chosen,它作为被选中对象信息记录的载体;
现在来看一下 point 的值到底是怎样计算出来的,
long oom_badness(struct task_struct *p, unsigned long totalpages)
{
long points;
long adj;
if (oom_unkillable_task(p)) ( 1 )
return LONG_MIN;
p = find_lock_task_mm(p); ( 2 )
if (!p)
return LONG_MIN;
adj = (long)p->signal->oom_score_adj;
if (adj == OOM_SCORE_ADJ_MIN ||
test_bit(MMF_OOM_SKIP, &p->mm->flags) ||
in_vfork(p)) { ( 3 )
task_unlock(p);
return LONG_MIN;
}
/*
* The baseline for the badness score is the proportion of RAM that each
* task's rss, pagetable and swap space use.
*/
points = get_mm_rss(p->mm) + get_mm_counter(p->mm, MM_SWAPENTS) +
mm_pgtables_bytes(p->mm) / PAGE_SIZE; ( 4 )
task_unlock(p);
/*
* Normalize to oom_score_adj units. You should never
* multiply by zero here, or oom_score_adj will not work.
*/
adj *= (totalpages + 1000) / 1000;
points += adj; ( 5 )
return points;
}
1)上面已提及;
2)TODO
3)取出该任务对应的 oom_score_adj 值,它可以用户态接口进行指定,范围是 [-1000, 1000],
4)统计该任务所占用的内存页面数并转存到 point;
5)计算该任务对应的 badness,涉及到的计算公式如下,

分数最高者那么将做为 OOM 的最佳对象。
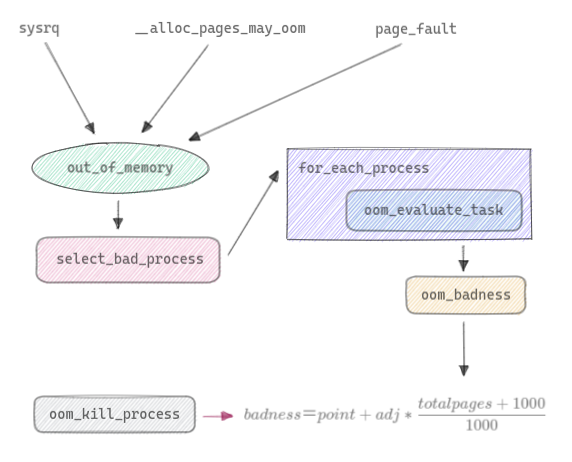
用一张图示总结一下上述的全部过程,当然 OOM 不仅仅只会在内存申请的过程中会触发到,也在 sysrq、page_fault 中有涉及,